
Text-to-speech synthesizer in nine Indian languages
Funding agency: Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) GmbH
The SYSPIN project from SPIRE Lab, IISc, Bangalore, in collaboration with Bhashini AI Solutions, has released TTS corpuses in 9 Indian languages with 2 speakers (male and female) per language. Over 40 hours of speech per speaker were recorded, ensuring high quality through rigorous checks, including local and native speaker contributions. The SYSPIN dataset and baseline TTS models are now available for download, empowering innovations in sectors like agriculture, healthcare, education, and finance. SYSPIN aims to advance multilingual, multi-speaker TTS systems, and organized challenges under LIMMITS 23, 24, and 25 to support inclusive, accessible voice technologies in India.
Learn more about the project
Learn more about the project
Speech Recognition in Agriculture and Finance for the Poor in India
Funding agency: Bill & Melinda Gates Foundation
Speech recognition in agriculture and finance for the poor is an initiative predominantly to create resources and make them available as a digital public good in the open source domain to spur research and innovation in speech recognition in nine different Indian languages in the area of agriculture and finance. Nine Indian languages considered for this project are Hindi, Bengali, Marathi, Telugu, Bhojpuri, Kannada, Magadhi, Chhattisgarhi, and Maithili.
Learn more about the project
Learn more about the project
Dysarthric Speech Analysis and Processing
Funding agency: DST, Govt. of India
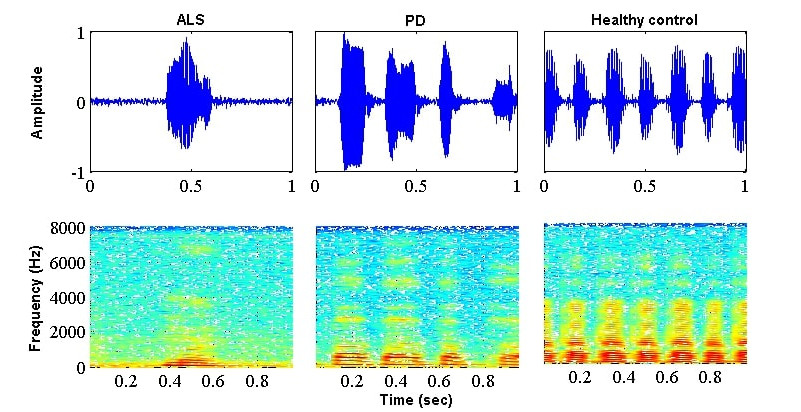
This project aims to understand the characteristics of dysarthric speech from the perspectives of signal processing as well as speech production. We further aim to utilize these insights in developing speech-based advanced tools and techniques which can enhance the quality of life of the individuals suffering from dysarthria.
Learn more about the project
Learn more about the project
Vaani
Funding agency: Google
Aims to capture the linguistic diversity of India to advance language AI technologies for an inclusive Digital India. The initiative plans to create a corpus of over 150,000 hours of speech from about 1 million people across all 773 districts, ensuring diversity in language, gender, age, and region. The dataset, which will include transcriptions in local scripts, will be open-sourced to support technologies like automatic speech recognition (ASR), speech-to-speech translation (SST), and natural language understanding (NLU). Google is funding the project to enhance language AI development.
Learn more about the project
Learn more about the project
ASR for Extremely Low-Resource Indic Languages
Funding agency: Ministry of Electronics and Information Technology (MEITy), Govt. of India
ASR for Extremely Low-Resource Indic Languages supports NLTM's objective by gathering data for three low resource languages languages, Konkani, Maithili and Santali
Learn more about the project
Learn more about the project
Meditation, Sleep Organization and Well-Being from an Indian Perspective: Evaluation of Micro Sleep Architecture Dynamics, Sleep Consciousness and Psychological Well-Being in Practitioners of Vipassana Meditation
Funding agency: DST, Govt. of India
Exploring the brain mechanisms associated with micro-sleep architecture dynamics among healthy practitioners of Vipassana meditation (who differ in their meditation proficiency) and control subjects.
An automated feedback system for degree of nativity in Indian spoken English learning
Funding agency: DST, Govt. of India
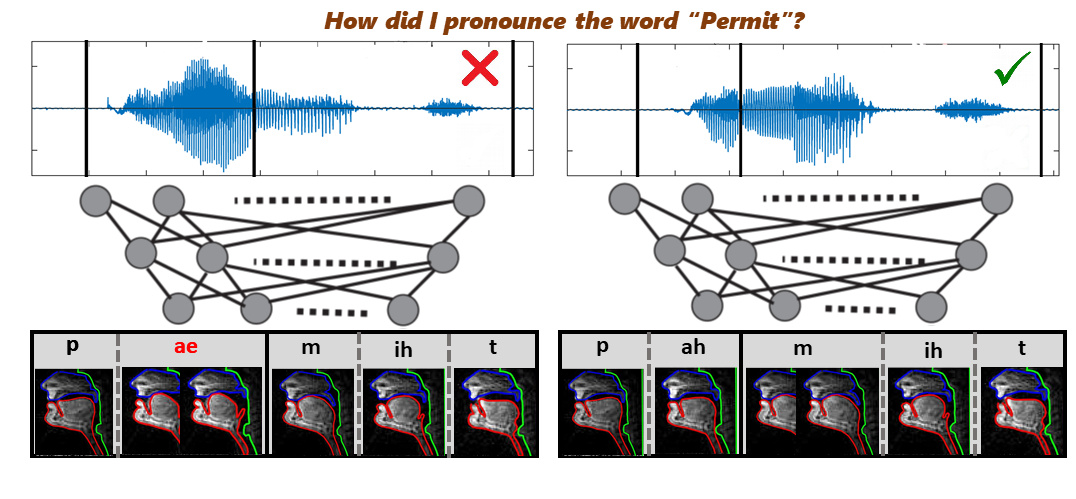
Developing a supervised system that predicts quantitative scores corresponding to the degree of nativity in the Indian spoken English and provides qualitative feedback according to the learners' nativity in an automated way.
Machine Intelligence for Cognitive and Communication Disorders
Funding agency: MHRD, Govt. of India
This project aims to address the gap between technological advancements and clinical intervention tools by developing automatic/semi-automatic analytical tools for speech and voice data that can be used to assist in the objective, quantitatively based diagnosis and treatment of speech and language difficulties associated with Autism Spectrum Disorder (ASD) and make it accessible to individuals of a variety of linguistic, cultural, and socioeconomic backgrounds in India.
English Gyani - An intelligent assistant for tutoring English via learner-tutor interactions
Funding agency: IMPRINT-IIC
'English Gyani' aims at improving one's English comprehension and reading skill with guidance in vernacular to cater to the increasing demand of English learning particularly for employment and promotions of individuals under-resourced to avail English learning materials or schools. The lessons are categorized to improve the vocabulary, grammar and sentence construction skills as parts of English comprehension.
Learn more about the project
Learn more about the project
Real time processing of VoIP Speech for Spoken keywords
Funding agency: DRDO, Govt. of India
This project aims to develop a robust keyword spotting system for VoIP speech in real time which involves several unique challenges that demand very fast processing of
concurrent sessions, high accuracy and minimal false alarms in the outputs, handling an unrestricted vocabulary and robust performance to codec and channel variations.
Learn more about the project
Learn more about the project
A communication theoretic approach to understand human speech communication system
Funding agency: DST, Govt. of India
Understanding of how various linguistic and paralinguistic components are exchanged in a human speech communication system could potentially be useful for making human-machine interaction natural.
Natural non-native English Speech synthesis
Funding agency: DST, Govt. of India
Development of a prototype device incorporating voice and breath sound analysis for quantification and monitoring of asthma
Funding agency: DBT, Govt. of India
Robot audition for source localization and separation using interaural cues
Funding agency: RBCCPS
Keyword spotting in continuous speech over VoIP channels and cellular networks
Funding agency: RBCCPS
Non-Contact Heart Rate Estimation from Facial Video
Funding agency: RBCCPS
Automatic evaluation of spoken English communication skill
Funding agency: RBCCPS
Synthesis of affective facial gestures for natural human-machine communication
Funding agency: DST, Govt. of India
Developing models for synthesizing facial expressions in various affective states would be useful for creating a natural agent in a human-machine communication, which could be used in a variety of applications including customer support which requires presence of an agent for interacting with the customers.
Development of a prototype device for the diagnosis of Obstructive Sleep Apnea using snore derived respiratory signal and pulse oximetry
Funding agency: DST, Govt. of India




