
Our research focuses on advancing articulatory speech synthesis through acoustic-to-articulatory inversion, leveraging a unique dataset of both acoustic and articulatory data. Using 14,260 utterances from 38 native Indian English speakers, we capture precise articulatory movements using electromagnetic articulography (EMA). With data from six key articulators—Upper Lip, Lower Lip, Jaw, and different parts of the tongue—we explore the relationship between these movements and the corresponding acoustic signals. This work aims to enhance speech synthesis, making it more natural and adaptable for applications in speech rehabilitation, language learning, and advanced human-computer interaction. By training models to generate realistic speech from articulatory data, we strive to push the boundaries of how speech can be synthesized and controlled.
Learn more about this project
A Text-to-Speech (TTS) corpus is a collection of recorded speech and corresponding text transcriptions used to develop and train TTS systems. These corpora are essential for creating high-quality TTS engines capable of generating natural-sounding speech from text input.
Please contribute your voice and help us improve our analyses.
Learn more about this project
Current clinical methods of diagnosis for asthma are evidently tedious, expensive and time-consuming. The motivation behind Asquire comes from developing a diagnosis method that is easy, yet effective and fast, using vocal sounds powered by Machine Learning (ML) and signal processing techniques.
Learn more about this project
Real-time magnetic resonance imaging (rtMRI) is an innovative tool that captures dynamic, detailed images of the moving vocal tract during speech production. It provides valuable insights into the coordination of speech articulators and vocal tract shaping, especially in regions difficult to visualize with other techniques. rtMRI plays a key role in advancing phonetic research, speech pathology treatments, and improving speech technology models like automatic speech recognition.
Learn more about this project
English Gyani' aims at improving one's English comprehension and reading skill with guidance in vernacular to cater to the increasing demand of English learning particularly for employment and promotions of individuals under-resourced to avail English learning materials or schools. The lessons are categorized to improve the vocabulary, grammar and sentence construction skills as parts of English comprehension.
Learn more about this project
We embed governing acoustic differential equations directly into deep neural networks to enable high-fidelity simulations of sound propagation. By leveraging GPU-accelerated Physics-Informed Neural Networks (PINNs), we systematically investigate the trade-offs between computational efficiency and accuracy across diverse applications—including geophysics, ultrasonics, speech, aerospace, and automotive acoustics. This ongoing research establishes a foundation for the next generation of predictive models in acoustics and related multiphysics domains.
Learn more about this project
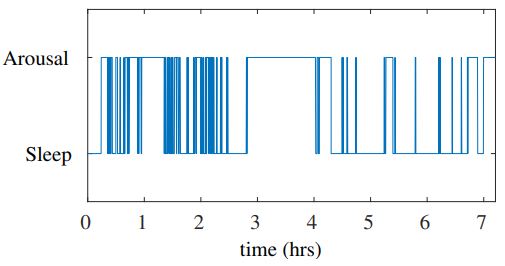
Sleep is controlled by the body's clock, the Circadian Rhythm. It is this continuous rhythm that alternates wakefulness and drowsiness in the day and night times, respectively. This rhythm can be altered with change in the timings of the activities performed by the person. Sleep has been shown as an important factor that determines the effectiveness of the work performed through the day. To deprive the body of healthy sleep means to deprive the body of its rest quotient. Healthy sleep helps rejuvenate the body, repair tissues, grow muscles, synthesize hormones, retain information better and perform well on memory related tasks. The process of sleeping consists of different sub-levels of wakefulness and sleep - REM and NREM. The study of sleep is usually done using Polysomnograph (PSG) signals acquired using bio-signal electrodes patched to a sleeping person. Through analysis of PSG signals, it is possible to identify sleep disorders like Insomnia, Sleep Apnea, Narcolepsy, etc.
Analysis of long duration PSG graphs is usually carried out by clinical experts who manually study the graph to label sleep stages, arousals and apnea. This project concerns the automation of the same task of characterizing signal patterns to classify sleep stages and detect abnormalities in the sleep cycle, using deep learning techniques.
Analysis of long duration PSG graphs is usually carried out by clinical experts who manually study the graph to label sleep stages, arousals and apnea. This project concerns the automation of the same task of characterizing signal patterns to classify sleep stages and detect abnormalities in the sleep cycle, using deep learning techniques.
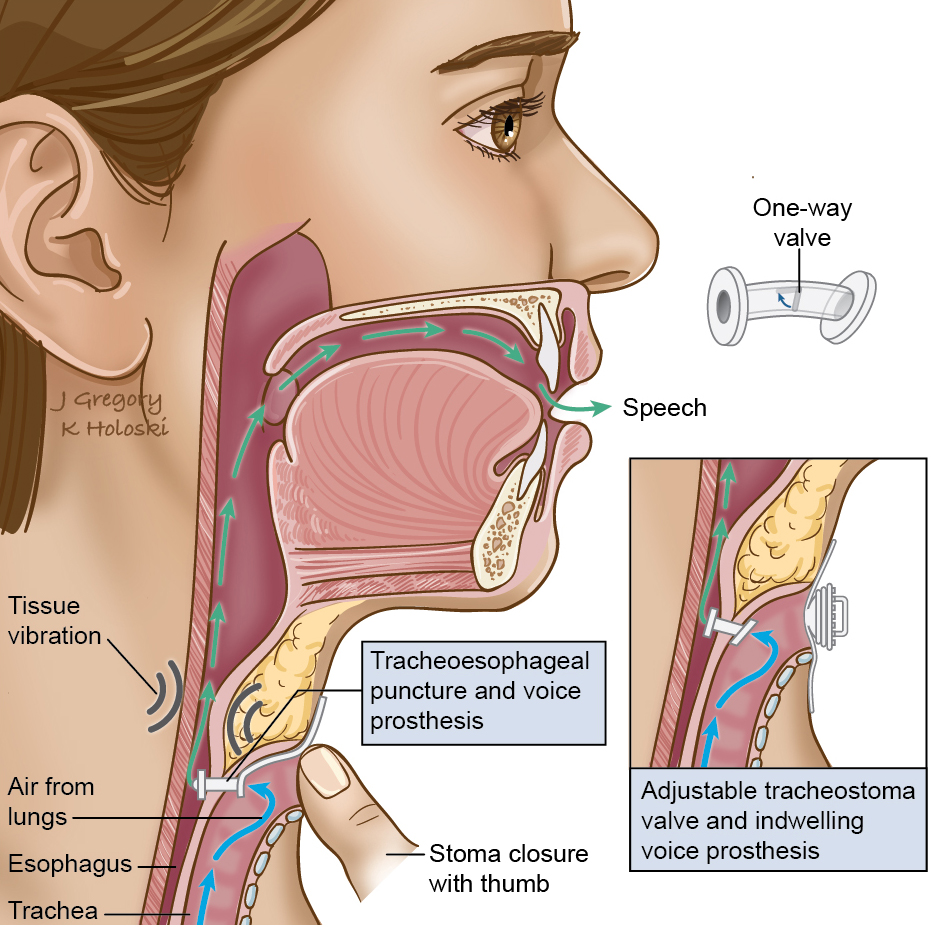
During advanced stages of cancers of the larynx and hypopharynx, a surgical procedure called laryngectomy is performed, in which cancerous regions, including the larynx or the voice box, are removed. In laryngectomees, in the absence of vocal folds, it is the vibration of the esophagus that gives rise to a low-frequency pitch during speech production, this speech is referred to as Tracheoesophageal speech. The tracheoesophageal (TE) speech is known to be hoarse,breathy and rough, which makes it difficult to understand. This work is about converting TE-speech to natural-sounding speech.
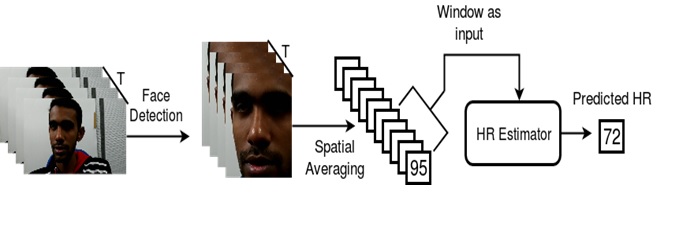
As the heart contracts and relaxes, the blood volume in the facial skin capillaries increases and decreases respectively. This causes a rhythmic variation in the pixel intensity values in the consecutive frames of the recorded facial video. Using this information, signal processing approaches as well as deep learning approaches were applied on the datasets recorded in IISc, to achieve a best mean absolute error of 2 BPM in a one minute video. The results were observed to be strongly varying with the subject and the light conditions.

Automatic methods for acoustic analysis and assessment of dysphagia in Head and Neck Cancer patients
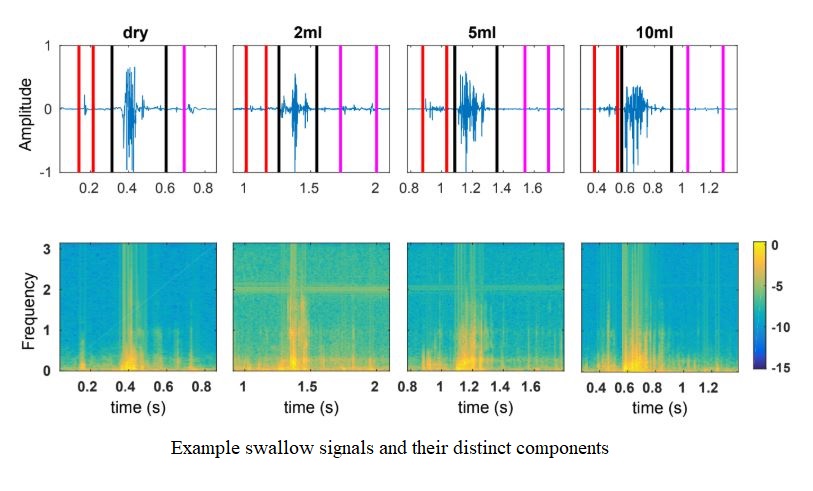

Patients with Head and Neck Cancer can experience dysphagia or more commonly known as swallowing disorders. Dysphagia can potentially lead to increased-risk medical conditions like pulmonary aspiration (both silent and overt), choking, fatigue and malnutrition. Such cases when unidentified can be fatal. The diagnosis of such disorders involves screening tests, and clinical assessments like fibreoptic endoscopy and videofluoroscopy. These techniques are invasive to the subject and can sometimes be harmful due to exposure to X-rays. Hence, in this project, the assessment of the physiology of swallowing is done using cervical auscultation (CA), where the swallowing action is captured by the sounds that are produced when the food bolus is swallowed. In CA, the sounds are picked up using an external stethoscope or microphone. The aim is to develop automatic methods to study the characteristics of swallow in both healthy and dysphagic subjects and also to detect the severity of dysphagia in Head and Neck Cancer patients, by leveraging signal processing and machine learning methods.
Initial work in this project involved feature learning for a volume dependent analysis and classification of water swallowed. Results indicated that, across different volumes, the acoustic features selected using automatic feature selection methods were more robust to volume changes than the baseline features that pertain to basic temporal and spectral parameters.
Initial work in this project involved feature learning for a volume dependent analysis and classification of water swallowed. Results indicated that, across different volumes, the acoustic features selected using automatic feature selection methods were more robust to volume changes than the baseline features that pertain to basic temporal and spectral parameters.
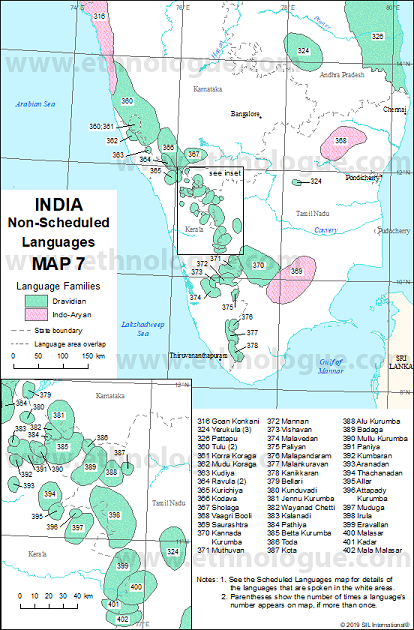
This study analyzes the effect of consonant context and speaking rate on vowel space and coarticulation in Toda vowel-consonant-vowel (VCV) sequences. All vowels /a/,/e/, /i/, /o/, /u/, and two intervocalic consonants, /p/ (labial) and /t/ (alveolar), are considered to form asymmetrical VCV sequences in slow and very fast speaking rates. Acoustic analysis using first and second formants (F1 and F2) shows a significant change in vowel space across speaking rates in a consonant specific manner. Quantification of range and extent of coarticulation using F2 are presented to carry out acoustic analysis of both anticipatory and carryover coarticulation. Significant V-V carryover coarticulation is observed in few VCV sequences with labial consonant. However, significant effect of consonant context is found for both anticipatory and carryover coarticulation in most of the VCV sequences. Increase in speaking rate is found to significantly drop both anticipatory and carryover co-articulation range in the context of alveolar consonants. Results from these acoustic analyses indicate that there are differences in the nature in which rate and consonant context affect the coarticulatory organization.
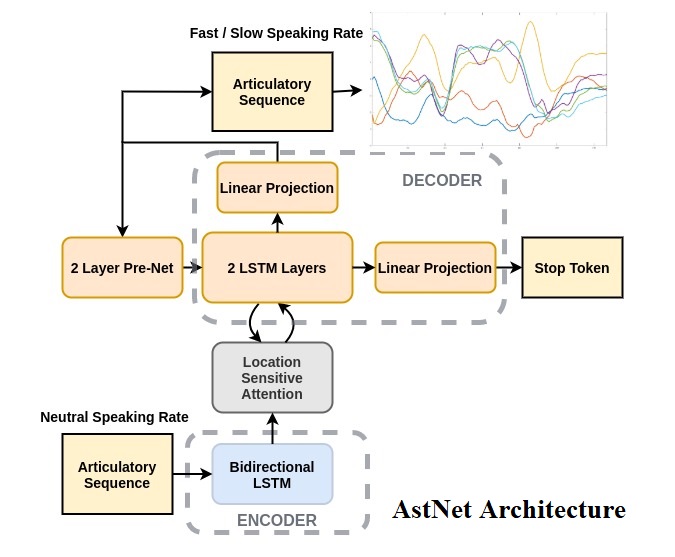
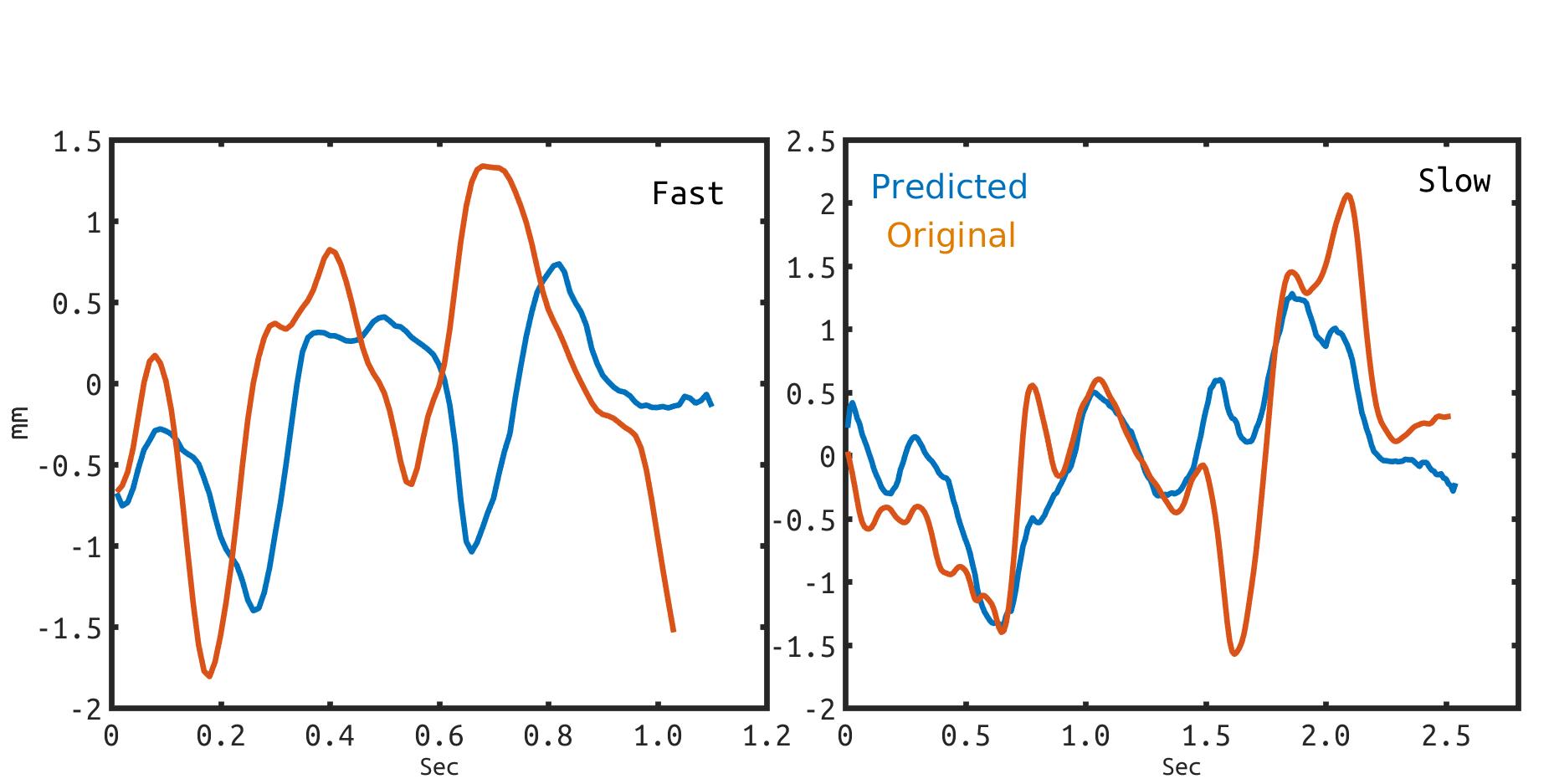
While speaking at different rates, articulators (like tongue, lips) tend to move differently and the enunciations are also of different durations. In the past, affine transformation and DNN have been used to transform articulatory movements from neutral to fast(N2F) and neutral to slow(N2S) speaking rates. In this work, we improve over the existing transformation techniques by modeling rate specific durations and their transformation using AstNet, an encoder-decoder framework with attention. In the current work, we propose an encoder-decoder architecture using LSTMs which generates smoother predicted articulatory trajectories. For modeling duration variations across speaking rates, we deploy attention network, which eliminates the need to align trajectories in different rates using DTW. We perform a phoneme specific duration analysis to examine how well duration is transformed using the proposed AstNet. As the range of articulatory motions is correlated with speaking rate, we also analyze amplitude of the transformed articulatory movements at different rates compared to their original counterparts, to examine how well the proposed AstNet predicts the extent of articulatory movements in N2F and N2S. We observe that AstNet could model both duration and extent of articulatory movements better than the existing transformation techniques resulting in more accurate transformed articulatory trajectories.
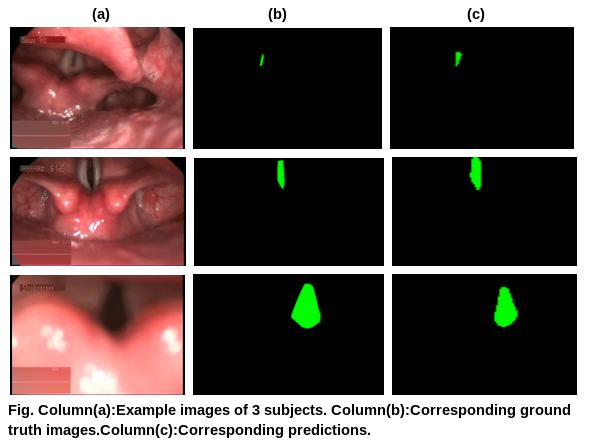
In speech production, vocal folds play a vital role in modulating airflow from lung through its quasiperiodic vibration. In between the vocal folds, a narrow opening is present which allows air to pass through the trachea called as glottis. The changes in shape or muscular properties of vocal folds lead to changes in the glottis opening. This causes variation in the voice like hoarseness and dysphonia. Many of these lead to an incomplete closure of the glottis during production of voice, this is termed as glottic chink. The glottic chink is typically visualized utilizing endoscopic or stroboscopic video by speech language pathologists (SLPs). This project aims at automatically localizing and segmenting the glottis in a stroboscopic video.
Learn more about this project
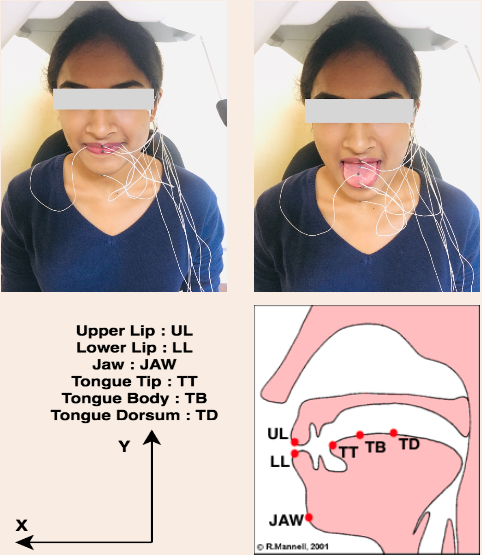
SPIRE VCV is a database of speech production, which includes simultaneous acoustic and electromagnetic articulography data collected from speakers of non-native/Indian English.
Stimuli comprises of non-sense symmetrical VCV (Vowel-Consonant-Vowel) utterances as part of the sentence speak VCV today in three different speaking rates: slow, normal, and fast with 3 repetitions each.
Stimuli comprises of non-sense symmetrical VCV (Vowel-Consonant-Vowel) utterances as part of the sentence speak VCV today in three different speaking rates: slow, normal, and fast with 3 repetitions each.
Learn more about this project

wSPIRE corpus is a multi device speech database having recordings in neutral and whispered mode.
88 speakers.
5 devices.
Parallel recordings in neutral and whispered speech.
The data was recorded in a soundproof recording room at the Electrical Engineering Department, Indian Institute of Science (IISc), Bangalore.
All the speakers are either graduate/interning students or employees at IISc.
88 speakers.
5 devices.
Parallel recordings in neutral and whispered speech.
The data was recorded in a soundproof recording room at the Electrical Engineering Department, Indian Institute of Science (IISc), Bangalore.
All the speakers are either graduate/interning students or employees at IISc.
Learn more about this project

Brief Description of the FAVIP database:
The FAVIP database consists of 15 subjects, 12 males and 3 females (as shown above). For each subject, ground truth pulse rate from a pulse-oximeter is provided along with simultaneously recorded one-minute videos taken by two cameras from Samsung S3 phone and iPhone 3GS phone. This recording is repeated at three camera-subject distances, namely 0.5, 1 and 2 feet.
To obtain a link for downloading the complete database, please email to prasantg@iisc.ac.in.
If you are using this database in a paper, please cite the following work:
Gaonkar, P. Aditya, R. Bhuthesh, Dipanjan Gope, and Prasanta Kumar Ghosh. Robust real-time pulse rate estimation from facial video using sparse spectral peak tracking. In Signal Processing and Communications (SPCOM), 2016 International Conference on, pp. 1-5. IEEE, 2016.
The FAVIP database consists of 15 subjects, 12 males and 3 females (as shown above). For each subject, ground truth pulse rate from a pulse-oximeter is provided along with simultaneously recorded one-minute videos taken by two cameras from Samsung S3 phone and iPhone 3GS phone. This recording is repeated at three camera-subject distances, namely 0.5, 1 and 2 feet.
To obtain a link for downloading the complete database, please email to prasantg@iisc.ac.in.
If you are using this database in a paper, please cite the following work:
Gaonkar, P. Aditya, R. Bhuthesh, Dipanjan Gope, and Prasanta Kumar Ghosh. Robust real-time pulse rate estimation from facial video using sparse spectral peak tracking. In Signal Processing and Communications (SPCOM), 2016 International Conference on, pp. 1-5. IEEE, 2016.




